알고리즘은 결국 성능과 연관이 있다.
아무리 코드가 짧더라도 for문이 중첩되어 있다면 그 코드는 BIG-O(n^2)가 되어버리는 것처럼 성능을 고민하면서 코드를 작성해야한다.
특히 파이썬의 경우 데이터를 다루는데 특화되어 있어 python module을 잘 활용하는것도 중요하다.
나는 알고리즘 문제풀이 초보지만 최대한 O(n)을 O(1)을 생각하면서 코드를 짠다.
그러다보니 문제 풀이 시간이 길어진다는 문제가 있는데 시간의 문제는 차차 나아질거라고 생각한다
고민의 시작은 시간이 아닌 나의 풀이는 항상 조금 길다는 것인데, 다른 사람의 풀이를 보게 되면 굉장히 짧아서 매번 충격에 압도된다.
오늘 알고리즘 풀이를 한 문제와 풀이는 아래와 같다.
이용자의 ID가 담긴 문자열 배열 id_list, 각 이용자가 신고한 이용자의 ID 정보가 담긴 문자열 배열 report, 정지 기준이 되는 신고 횟수 k가 매개변수로 주어질 때, 각 유저별로 처리 결과 메일을 받은 횟수를 배열에 담아 return 하도록 solution 함수를 완성해주세요.
나의 풀이 코드
from collections import defaultdict
def solution(id_list, report, k):
# id_list : 전체 유저 목록
# report : ["frodo neo", "muzi con"] : frodo->noe 신고, muzi->con 신고
# k : 정지 카운트
# answer : 정지 메일 확인
bad_count = defaultdict(lambda :0)
man_report = {}
mails = defaultdict(int)
users = defaultdict(list)
for r in report:
m_b = r.split(" ")
reporter = m_b[0] # 신고자
bad_man = m_b[1] # 신고당한사람
# 신고 리포트
if reporter not in man_report:
man_report[reporter] = [bad_man]
bad_count[bad_man] += 1
elif bad_man not in man_report[reporter]:
man_report[reporter] += [bad_man]
bad_count[bad_man] += 1
# 정지 유저
stop_user = set([m for m, c in bad_count.items() if c >= k])
# 정지 유저들을 신고한 유저에게 이메일 발송 카운트
# 두 셋 비교
for man, report in man_report.items():
# man 신고자
# report : List -> 신고 유저 리스트
count = len(set(report).intersection(stop_user))
mails[man] = count
# id_list에 대응하는 메일 발송 리스트
for user in id_list:
users[user] = mails[user]
answer = list(users.values())
return answer
딱 봐도 길지만 나는 주어진 조건 "1 ≤ report의 길이 ≤ 200,000" 을 주목했다.
실 활용에서는 이것보다 더 긴 데이터가 나올 수 있다고 생각이 들었고, 결국은 굉장히 긴 데이터를 처리하려면 속도가 중요할 거라고 생각했다.
나는 report 를 split 하는 함수를 최대한 한번만 사용하고 싶었다. 200,000개의 list를 분석하는 for문을 최대한 낭비없이 활용해야 할거라고 생각했다. 그래서 첫번째 split을 하는 for 문 길이가 길어졌다.
두번째 세번째 for문도 중첩활용 없이 for문만 적용하면 전체 코드는 길지만 분명 dict을 활용한 코드기 때문에 속도에는 크게 지장이 없을거라고 생각하고 코드를 작성했다.
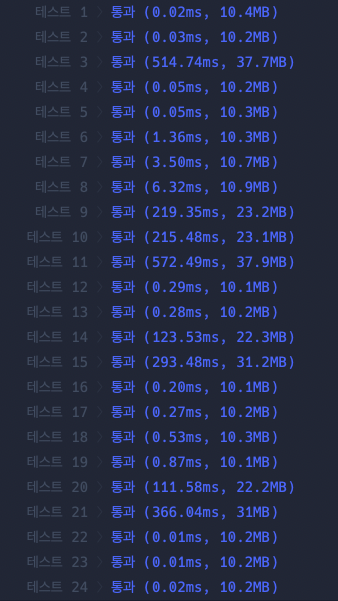
테스트 코드 결과이다.
이제 다음은 내가 보고 너무너무 감탄한 훌륭한 코드, 파이썬스러운 코드라고 생각이 들었던 코드이다.
def solution(id_list, report, k):
answer = [0] * len(id_list)
reports = {x : 0 for x in id_list}
for r in set(report):
reports[r.split()[1]] += 1
for r in set(report):
if reports[r.split()[1]] >= k:
answer[id_list.index(r.split()[0])] += 1
return answer간단하면서 for문에 앞서 set으로 중복을 제거하고 id_list.index()를 사용하는 굉장한 센스..
내 코드에 비해 압도적으로 짧은 코드.
사실 결과를 떠나 이런 활용이나 센스는 훌륭하고 언젠가 나도 계속 짜다보면 활용 할 수 있는 날이 올거라고 믿고 싶다.
어찌됐든 테스트 코드 실행 결과

나는 테스트 3번과 20, 21번 문항에서 속도차이가 2배이상 나는 것을 보며 고민이 깊어졌다.
report를 두번 spllit하는 아래 코드에서는 report의 길이가 굉장히 길 경우 많은 속도차이를 내게 된거라고 짐작한다.
내 코드가 좋다고 하는게 아니라 알고리즘 풀이 공부의 궁극적인 목적을 어디에 두고 고민하면서 풀어야 할지 생각하게 되었다.
빅 데이터를 다루면서 좋은 성능을 낼 수 있는 코드를 짜고 싶은 욕심이 있고, 알고리즘의 풀이를 간단하면서 빠르게 풀어내고자 하는 욕심도 있다.
오늘 알고리즘 풀이를 하면서 여러 생각에 잠겼다.
처음에는 같은 결과를 만들어 내는 각기 다른 코딩에 매력을 느꼈지만 이것이 곧 성능에 직결된다는 것.
내가 추구하는 두 가지를 얻으려면 많은 고민과 꾸준한 공부가 바탕이 되어야 할 것이다.
'TIL' 카테고리의 다른 글
| [12시간 삽질기].. 아나콘다 파이썬 버전 변경 오류 주의점 (4) | 2022.05.11 |
|---|---|
| [Python] List 연산 주의점 (0) | 2022.05.04 |
| [python] decorator 파이썬 데코레이터 이해하기 (0) | 2022.01.22 |
| [python] in 연산자의 실행시간, 시간 복잡도 BigO (0) | 2022.01.07 |
| 윈도우11 oh my posh 터미널 꾸미기 (0) | 2021.12.31 |


댓글